I have been fascinated by image captioning for some time but still have not played with it. I gave it a try today using the open source project neuraltalk2 written by Andrej Karpathy.
The theory
The working mechanism of image captioning is shown in the following picture (taken from Andrej Karpathy).

The image is encoded into a feature vector by a convolutional neural network (CNN) and then fed into a recurrent neural network (RNN) to generate the captions. The RNN works word by word. Each time it receives an input word and a hidden state and generates the next word, which is used as the input word in the next time. The CNN feature vector of the image is used as the initial hidden state, which is updated in each time step of the RNN.
In the above picture, the RNN receives the initial hidden state and START (a special word incidating the RNN to start generation) and generates the first word straw. Then straw is fed into the RNN together with the updated hidden state to generate hat. Finally, hat is fed into the RNN with the latest hidden state to generate END (a special word indicating the RNN to stop). So the caption of the image is straw hat.
The experiment
I played with neuraltalk2 to get a sense of how image captioning performs.
Working environment
I ran the code in a VM instance of Google Cloud. If you also want to use Google Cloud, you may refer to the Google Cloud Tutorial of CS231n to learn about how to set up a virtual instance. The tutorial is a bit long and you should only need to reach Connect to Your Virtual Instance.
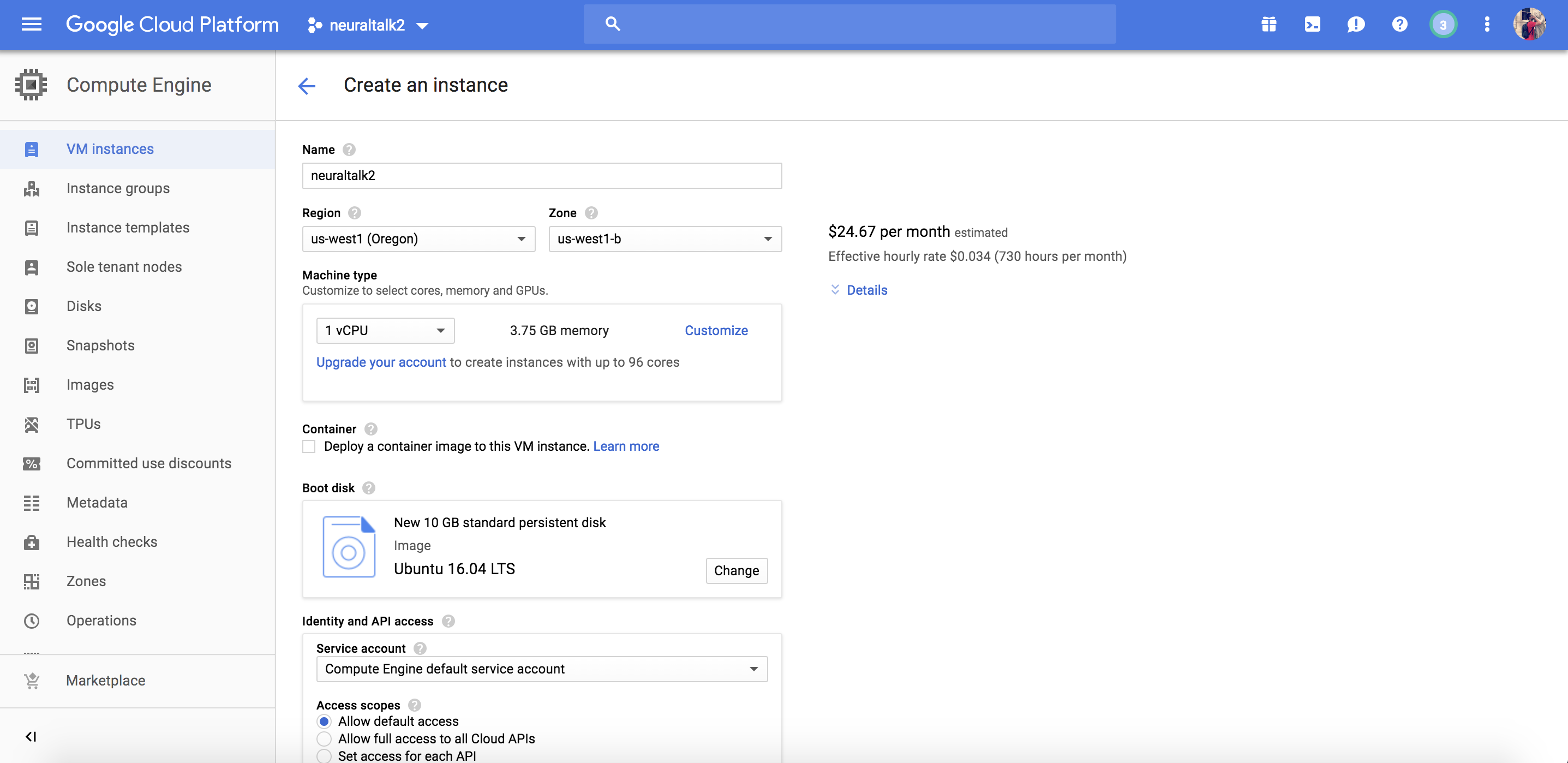
The following screenshots show the settings of the VM instance. I made several changes:
- Changed Name to neuraltalk2
- Changed Region and Zone to us-west1 (Oregon) and us-west1-b
- Changed Boot disk to Ubuntu 16.04 LTS
- Checked Allow HTTP traffic and Allow HTTPS traffic
Installing Torch
neuraltalk2 is written in Torch. So you need to install Torch first. You can simply follow the steps in Getting started with Torch:
$ git clone https://github.com/torch/distro.git ~/torch --recursive
$ cd ~/torch; bash install-deps;
$ ./install.sh
At the end of the last command, you will be prompted a question. Just answer yes.
Do you want to automatically prepend the Torch install location
to PATH and LD_LIBRARY_PATH in your /home/jianchao/.bashrc? (yes/no)
[yes] >>>
yes
Finally, run
$ source ~/.bashrc
Now Torch should be ready.
Installing dependencies
I ran neuraltalk2 on the CPU (since GPU is very expensive in Google Cloud). So I only need a part of the dependencies. I ran the following commands from my $HOME directory to install the dependencies.
$ luarocks install nn
$ luarocks install nngraph
$ luarocks install image
$ # Install Lua CJSON
$ wget https://www.kyne.com.au/~mark/software/download/lua-cjson-2.1.0.tar.gz
$ tar -xvzf lua-cjson-2.1.0.tar.gz
$ cd lua-cjson-2.1.0
$ luarocks make
$ cd # go back $HOME
$ # Install loadcaffe
$ sudo apt-get install libprotobuf-dev protobuf-compiler
$ CC=gcc-5 CXX=g++-5 luarocks install loadcaffe
$ # Install torch-hdf5
$ sudo apt-get install libhdf5-serial-dev hdf5-tools
$ git clone https://github.com/deepmind/torch-hdf5
$ cd torch-hdf5
$ luarocks make hdf5-0-0.rockspec LIBHDF5_LIBDIR="/usr/lib/x86_64-linux-gnu/"
$ cd # go back $HOME
Notice that Andrej listed loadcaffe and torch-hdf5 under For training, but they are actually also required for inference. And if you woud like to run neuraltalk2 on a GPU, please follow the README.md to install those additional dependencies.
Captioning images
Now we can use neuraltalk2 to caption images. Just clone the repository and download the pretrained model. Since I ran it on CPU, I downloaded the CPU model. You may need to download the GPU model to run it on GPU.
$ git clone https://github.com/karpathy/neuraltalk2.git
$ cd neuraltalk2
$ mkdir models
$ cd models
$ wget --no-check-certificate https://cs.stanford.edu/people/karpathy/neuraltalk2/checkpoint_v1_cpu.zip
$ unzip checkpoint_v1_cpu.zip
I created another folder images in the root directory of neuraltalk2 to store the test images. I downloaded two datasets for the experiment: the [2017 Val Images of COCO](2017 Val images [5K/1GB]) and the Clothing Co-Parsing (CCP) Dataset.
After everything is ready, just run the following command to apply neuraltalk2 to caption the images. Since I used CPU, I set -gpuid -1.
th eval.lua -model models/model_id1-501-1448236541.t7_cpu.t7 -image_folder images/ -num_images -1 -gpuid -1
Results
COCO

In the COCO dataset, images are of various scenes and objects. And neuraltalk2 is able to capture the overall content of what is happening in the image, except for some mistakes like the cat is not sitting on the laptop. But, in general, the captions are very discriminative considering the large differences between images. Given images and captions, it is very easy to tell which image corresponds to which caption. Image captioning makes great sense in this case.
CCP

In the CCP dataset, images are all coming from the clothing domain and thus they are very similar to each other in the overall content. And the differences are mostly reflected in fine-grained details. In this case, the captions of neuraltalk2 which only capture the overall content become meaningless and are not very helpful for distinguishing one image from others. Moreover, the captions make more mistakes, like a lot of false positives of cell phones.
Thoughts
For classifying images in the same domain, researchers have come up with fine-grained image classification. Now to caption these images, whose fine-grained details are much more important than the overall content, it makes sense to state that we need fine-grained image captioning.
To solve the fine-grained image captioning problem, we need to collect a dataset of images in the same domain with fine-grained captions. The considerable number of advertising captions for clothes/food/cars serve as a good basis. The pipeline of fine-grained image captioning may also be similar to that of general image captioning: a CNN learns a domain-specific representation of the image (maybe via fine-tuning the network in a fine-grained image classification task) and then an RNN generates a fine-grained caption conditioned on the representation. There should be many problems waiting to be discovered and solved in fine-grained image captioning.